As with transcription tools and schemes, software toolkits for coding and analysing data are selected for their suitability to the type of data and analysis needed.
Some of the main considerations and criteria when selecting a toolkit for annotation and analysis of multi-modal data include:
- Synchronising text and audio/video
- Interoperability of files and platforms, importing and exporting data
- Separability of modes
- Ease of use (this includes a brief overview of currently available software for coding and analysis, including ELAN, Praat, ANVIL, amongst others)
Synchronising text and audio/video
One of the main differences between standard text-based corpora and a multi-modal corpus is the need to align multiple streams of data. When bringing together text and audio or video we need to be able to synchronise concurrent linguistic and non-linguistic features. In the context of the IVO project, we need to be able to represent different dimensions of interaction, across multiple participants, both on a sequential and simultaneous level. For example we wish to capture linear sequences of individual modes from individual participants, (such as stream of speech, captured as text) and multiple modes happening simultaneously (such as nodding while responding, or smiling while listening, captured through video). All standard video and audio files contain timelines and these become a convenient anchor for the alignment of text and other data streams. As Adolphs et al. point out ‘the advantage with utilising video and audio files is that they are time-based, so theoretically the synchronisation of these media files can be carried out with relative ease’ (2011: 316).
Interoperability of files and platforms, importing and exporting data
Multi-modal data is gathered in a variety of file types, supporting video, audio and text. (e.g. .mp4, .wav, .srt, .txt, .doc)
Some tools allow for text to be integrated either through a manual transcription function within the tool itself or by importing files of text transcription. Some automatic speech recognition transcription tools (e.g. Otter) have a range of options for transcription outputs (e.g. .txt files, .srt files, .pdf, .doc). The ideal toolkit for coding and analysis accommodates a variety of file types, both for importing and exporting data.
Separability of modes
Speech is just one of the modes captured in MM analysis. In standard text-based corpora, speech is typically represented in written text form and text is used as the principal entry point for analysis. In MM analysis all modes can be treated as equal, which means that in terms of communicative value, non-vocal communication is on an equal footing with vocalised communication. If we are to take an ‘all-modes-are-equal’ approach, we need software which can represent and support modes separately so that any mode or aspect of a mode can be used as the entry point for analysis. Software such as ANVIL, ELAN and EXMaRaLDA facilitates this through the creation of a series of separate multi-layered tracks or tiers, representing separate modes or aspects of modes.
Ease of use: annotation, searchability, visualisation
MM data can require multiple levels of annotation because of the complex, multi-layered nature of the data. As Knight et al. describe ‘with a multi-media corpus tool it is difficult to exhibit all features of the talk simultaneously. If all characteristics of specific instances where a token, phrase or coded gesture (in the video) occur in talk are displayed, the corpus software tool would have to involve multiple windows of data including concordance viewers, text viewers, audio and video windows.’ (2009: 21). Since MM corpus analysis is still relatively new within corpus linguistics, ideally we need tools which are intuitive and accessible to novice users who may or may not already be familiar with traditional corpus annotation and which provide clear step by step guidance for use. Ideally tools should allow for real-time annotation, as well as the option to speed up or slow down media playback to allow for greater accuracy in alignment of annotations. Platforms that incorporate co-representation and searchability of annotation in all components simultaneously are desirable.
Brief overview of available tools:
The toolkit that we are using for the IVO project is ELAN. It has been selected as it offers all of the features described above.
ELAN is a free, open source software that allows for extensive annotation of multi-modal data developed by Max Planck Institute for Psycholinguistics, The Language Archive, Nijmegen, The Netherlands. Wittenburg et al. (2006).
Extensive information and documentation about ELAN can be found here: https://archive.mpi.nl/tla/elan
ELAN was originally conceived in 2001 and since that time has undergone regular of changes and improvements in features, the latest release at the time of writing being version 6.4, in July 2022.
ELAN presents data in a timeline format, and transcription can be separated into various modalities (e.g. speech, gesture, gaze) in multiple layers or tiers which can be hierarchically structured and connected. ELAN has all the standard functionalities of a transcription software including multi-modal data playback, and audio representation as waveform or pitch contour. Presentation within ELAN is much like timeline multi-modal transcription, in which sequence, duration and co-occurrence of actions is easy to recognise. ELAN aims to be compatible with other multimodal analysis software, and thus data from ELAN can be exported to a number of other programs. ELAN has one of the best layouts for developing extensive transcription, as its timeline style layout is conducive to a finalised transcription.
Main features and characteristics of ELAN (https://archive.mpi.nl/tla/elan):
- provides flexible, multiple ways to view annotations, each view is connected to and synchronized with the media timeline
- supports creation of multiple tiers and tier hierarchies
- supports Controlled Vocabularies, allowing for consistency across annotation and annotators
- allows linking of up to 4 video files with an annotation document
- media support: builds on existing, native media frameworks, like Windows Media Player, QuickTime or VLC; supports high performance media playback.
- technical: operates across Windows, macOS and Linux; is open source, the sources are available under a GPL 3 license
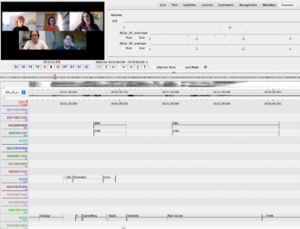
Figure 1: Example of ELAN file with multiple tiers
Other available resources:
Other toolkits which have been used for previous multi-modal studies, specifically the annotation and analysis of multimodal linguistic corpora, include:
Click on each tool for further information.
Anvil
ANVIL http://www.anvil-software.de describes itself as a ‘free video annotation tool’. It allows for multi-layered information to be coded along a series of different level ‘tracks ‘which can also be colour-coded as per the user’s preference. ANVIL also provides a timeline of the multimodal text. It allows users to play videos within the software, and where there is audio data can present this information as a waveform or pitch contour. ANVIL also tracks and pinpoints position within the transcribed text as the video plays. Whilst one can transcribe speech manually through ANVIL’s text tools, it is also possible to import pre-existing transcripts created in other software programs. For example, ANVIL can import from PRAAT and ELAN if initial software work has been conducted through these programs.
ANVIL was developed by Michael Kipp. Kipp, M. (2001) Anvil – A Generic Annotation Tool for Multimodal Dialogue. Proceedings of the 7th European Conference on Speech Communication and Technology (Eurospeech), pp. 1367-1370. The most recent version of ANVIL (6) was released in 2017. Other references and further information can be found here: http://www.anvil-software.de/
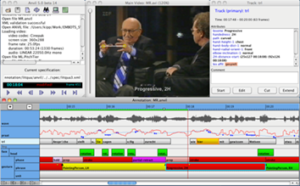
Figure 2: Example of ANVIL interface file with multiple components
ChronoViz
ChronoViz http://chronoviz.com is described as a ‘tool to aid visualization and analysis of multimodal sets of time-coded information’, and as such it excels at presenting multiple different pieces multi-modal data simultaneously, and showing how they progress through time. It also has tools for adjusting the speed of playback for each of the data sets being displayed. ChronoViz was developed by Adam Fouse while at Distributed Cognition and Human-Computer Interaction Laboratory at the University of California, San Diego (http://adamfouse.com/software.html) Fouse et al. (2011).
Further information can be found here: http://chronoviz.com
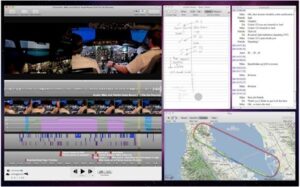
Figure 3: Example of ChronoViz interface
Figure 3 shows an example from recordings of two men landing an aeroplane. There is video data recorded from their perspective, and from a camera set behind them. There is an audio waveform, a graph showing velocity (presumably of the plane), a map of their flight, a reproduction of digital notes taken and a speech transcript. ChronoViz excels at displaying many different types of time-series information whilst maintaining the accessibility of each data set. Unfortunately, ChronoViz does not have a cohesive export option. Parts of the information can be exported, such as annotations of data, parts of video clips and screenshots of timelines; but information coded in ChronoViz cannot be automatically exported as a completed transcript.
CLAN
CLAN https://dali.talkbank.org/clan/ was developed in tandem with the CHILDES project in 1984 as a component of the TalkBank system https://childes.talkbank.org. CLAN is a multi-functional software dealing with aspects both of transcription, and corpus creation, analysis and data sharing. Similarly to ChronoViz, CLAN allows simultaneous portrayal of original media and the transcript being produced. It is regularly updated (most recently in December 2022).
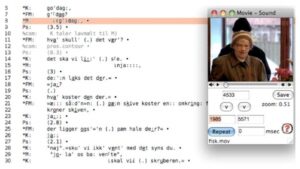
Figure 4: Example of CLAN interface
CLAN also links transcribed data to the original media temporally, which allows for the original media to be played while relevant material in the text transcript is highlighted. Much like previously discussed software, CLAN also has resources to display audio in waveform or pitch contour format. CLAN is designed to work alongside PRAAT which is a more specialised phonetics software. An important function of CLAN is ease of sharing via TalkBank, allowing for the development of corpora. This interface was designed for a more CA-type annotation than the annotation approach adopted in the IVO project which is why it was not selected for use.
EXMARaLDA
EXMARaLDA https://exmaralda.org/en/about-exmaralda/ is similar to ELAN in terms of functionality. Also freely available, it describes itself as a ‘system for working with oral corpora on computer’.
There is detailed information about the system here: https://exmaralda.org/en/about-exmaralda/
The most recent version was released in 2019, and a preview version of an upcoming version was released in September 2022.
ExMARaLDA consists of several components:
-
- a transcription and annotation tool (Partitur-Editor)
- a tool for managing corpora (Corpus-Manager) and
- a query and analysis tool (EXAKT).
The system is described in Schmidt T and Wörner K (2014), “EXMARaLDA”, In Handbook on Corpus Phonology, pp. 402-419. Oxford University Press.
The main features of ExMARaLDA include[DK1] [GM2] :
-
- time-aligned transcription of digital audio or video
- flexible annotation for open categories
- systematic documentation of a corpus through metadata capture
- flexible output of transcription data in various layouts and formats (notation, document)
- computer-assisted querying of transcription, annotation and metadata
- interoperable as it works XML based data formats that allow for data exchange with other tools (like Praat, ELAN, Transcriber etc.) and enable a flexible processing and sustainable usage of the data
ExMARaLDA has been used extensively across a wide range of projects over the past 20 years. There is detailed information about these projects from the EXMARaLDA website here: https://exmaralda.org/en/projects/
ExMARaLDA has been used for:
-
- conversation and discourse analysis,
- study of language acquisition and multilingualism,
- phonetics and phonology,
- dialectology and sociolinguistics.
EXMARaLDA is hosted as an open source project on GitHub.
Please cite EXMARaLDA by referring to the website (www.exmaralda.org) and the latest publication describing the system, which is:
Schmidt T and Wörner K (2014), “EXMARaLDA”, In Handbook on Corpus Phonology, pp. 402-419. Oxford University Press[DK3] .
While on a par with ELAN in terms of functionality and features, it was marginally less easy to install for both Windows and Mac use. Use of ELAN and support for use also appears to be more widely documented.
Praat
Praat http://www.praat.org/ is a free software tool developed by Paul Boersma and David Weenink with many resources to aid speech analysis. It is widely used for phonetic and phonological research. https://www.fon.hum.uva.nl/praat/manual/Intro.html The latest version of Praat (6.3.03) was released in December 2022. Audio files can either be created by recording through Praat, or imported into the software. Praat can present this audio in a number of formats, including waveform but also more specialised forms such as energy spectrograms.
Figure 5: Example of the Praat interface
Other windows within the Praat software can help analyse this data, such as resources for pitch tracking, formants, nasality, amplitude and more. Praat aims to be a comprehensive tool for audio analysis, and as such has more extensive tools than most multimodal transcription software. Praat can also help modify recorded audio. Data analysed within Praat can be exported into many other transcription programs. Praat, therefore, may be useful in conjunction with other programs which allow for video analysis.
Transana
Transana https://www.transana.com/products/transana-basic/ is a multi-modal analysis software capable of dealing with text, still-frame images, video and audio within a single analytical frame. Much of Transana’s focus lies with transcription and data organisation so as to make it easier to manage. However, like other software, it can display data in the most common formats: video player, waveform audio, transcribed speech and so on. A progressive element of Transana is the capacity to share a project between multiple researchers. Different users can work on the same data simultaneously from different locations, with changes happening in real time. Combined with a conference call, this could be effective for collaborative work. Transana also has search tools than can isolate data within a larger field, though this is not a unique feature as it is also characteristic of ELAN and ExMARaLDA, for example. It is widely used across academic, public sector and commercial contexts worldwide (https://www.transana.com/about/publications/) and there are a range of subscription options available for its use (https://www.transana.com/products/). A free demo version is available here https://www.transana.com/about/demo/
![]()
Figure 6: Example of the Transana interface
The following tools were also designed for analysing video data. There are also other commercially available tools, requiring purchase or subscription.
|
ORIONTM Previously known as Constellations and WebConstellations |
http://orion.njit.edu/ unsure about status of this project as there is no response to the link |
Designed to specifically link and present pre-coded and pre-transcribed data |
|
Dynapad |
https://hci.ucsd.edu/lab/dynapad.htm
|
This is a multiscale interface and visualization software. It makes scale a first-class parameter of objects, supports navigation in multiscale workspaces, and provides special mechanisms to maintain interactivity while rendering large numbers of graphical items |
|
I-Observe |
http://www.iobserve-app.com/products.html
|
iObserve is a video and audio recording app or desktop device that allows you to record observations, time stamp criteria, give instant feedback and automatically create a signed report. It is widely used professionally in interview or assessment contexts. |
|
Diver |
|
Digital Interactive Video Exploration and Reflection A tool, for capturing annotating and sharing DIVES on video offering a unique annotated perspective on a video recording of human activity. |
References
Adolphs, S., Knight, D., & Carter, R. (2011). Capturing context for heterogeneous corpus analysis: Some first steps. International journal of corpus linguistics, 16(3), 305-324.
Boersma, Paul & Weenink, David (2022). Praat: doing phonetics by computer [Computer program]. Version 6.3.03, retrieved 17 December 2022 from http://www.praat.org/
Fouse, A., Weibel, N., Hutchins, E. and Hollan, J.D. (2011). ChronoViz: A system for supporting navigation of time-coded data, Proceedings of CHI 2011, SIGCHI Conference on Human Factors in Computing Systems: Interactivity Track, Vancouver, Canada, May 2011 (pdf).
Kipp, M. (2001) Anvil – A Generic Annotation Tool for Multimodal Dialogue. Proceedings of the 7th European Conference on Speech Communication and Technology (Eurospeech), pp. 1367-1370.
Knight, D., Evans, D., Carter, R., & Adolphs, S. (2009). HeadTalk, HandTalk and the corpus: Towards a framework for multi-modal, multi-media corpus development. Corpora, 4(1), 1-32.
Schmidt T. and Wörner K. (2014), EXMARaLDA, in The Oxford Handbook of Corpus Phonology, pp. 402-419. Oxford University Press.
Wittenburg, P., Brugman, H., Russel, A., Klassmann, A., Sloetjes, H. (2006). ELAN: a Professional Framework for Multimodality Research. In: Proceedings of LREC 2006, Fifth International Conference on Language Resources and Evaluation.