Using a Speech-to-text Tool in Multi-modal Corpus Construction
This document assesses the potential for using a speech-to-text tool to create orthographic transcriptions for integration into a multi-modal corpus. The document describes:
- selecting an appropriate speech-to-text tool,
- the typical features of a speech-to-text tool (as used in the IVO project),
- the procedure for using the tool in creating an orthographic transcription,
- the exportation of transcriptions, for integration into multi-modal corpus software, and,
- challenges and limitations of using a speech-to-text tool.
Though this document focuses on one tool for the purposes of orthographic transcription (i.e. Otter.ai), there are a range of other options available, including manual transcription. There are also several other speech-to-text tools available that may be preferable to Otter, which are listed at the end of this document.
(Note, for details of the data capturing stage, see data capturing guidelines).
Selecting a speech-to-text tool
With an abundance of tools available to facilitate automatic speech-to-text transcription, selecting a suitable tool for a given project can prove difficult with each tool providing varying features. The IVO project explored options through experimentation with different tools such HappyScribe, Scribie and Otter and investigated comparative reviews of tools before selecting Otter for for its accuracy, ease of access, flexibility with various file formats and relative low cost.
Otter is a cloud-based platform accessible through an account set up via Otter.ai which facilitates ease of collaboration through sharing transcripts that others can edit, which is important for a multi-institutional, collaborative project such as IVO. Otter facilitates the exportation of transcripts via various formats, including SRT which, as will be explained, is compatible with constructing time-aligned, segmented transcripts when imported into the ELAN.
Cost: Otter has four different plans (Basic, Pro, Business and Enterprise) which provide the user with expanding minutes of transcripts and numbers of transcripts permitted per month. Otter’s Basic free plan exports only as rtf, pro version allows for various export types including DOCX, PDF and SRT. The free plan is limited to 30 minutes of transcription.
The Pro plan is suitable for the needs of the IVO project. Details of the pricing for this plan can be found here. To access the reduced rate, the user must log in with a school/university email. As these tend to change regularly, for up-to-date information regarding Otter’s plans see https://Otter.ai/pricing.
- Accuracy: While reviews claim that Otter creates transcripts that are 95% accurate, this level is difficult to determine as it is highly dependent on the sound quality of a recording, the amount of overlapping dialogue and the clarity of speech of the participants. Capacity to quickly process multiple formats of video and audio: Audio only upload and transcription of 13.358 MB m4a file of 34 minutes and 12 seconds took ten minutes. During this stage, the user can access the transcription as it is processing. There is an option available for Otter to send the user a notification when the transcription has fully processed.
Features of Otter.ai
In addition to the features listed above Otter has a number of other features which may be of interest to users:
- A ‘Personal Vocabulary’ function which gives the user the option to insert items which may be unique to the user such as names of people for Otter to notice. After these have been inserted, Otter will recognise these for future transcriptions.
- A ‘My Agenda’ feature which supports integration with Gmail Calendar, Zoom and Microsoft Outlook to ‘streamline your workflow’.
- Files can be synced directly to and from Dropbox which may be of interest to those with a preference for cloud storage and sharing using this platform.
- the ability to directly record conversations on your device
- Members of a project can message each other directly through Otter which can provide an efficient way of communicating to project members about, for example, transcription conventions.
- While checking transcriptions, playback can be set to different speeds which can aid determination of items that may be difficult to hear at normal speed and there is an option to ‘skip silence’ for users who are not interested in phases of silence that may exist in some recordings.
- Speakers are automatically identified and tagged throughout transcriptions and across different transcriptions when it recognises the same speakers. This is useful for efficient tagging of speakers which can be difficult without video playback.
- Speakers are assigned percentages tallying with the amount of speech they occupy in the conversation which provides an overview of who speaks most and least in a recording.

- Otter lists summary keywords of terms which are frequent in a transcript providing an overview of salient topics in a transcript.

- Otter has a mobile app which connects to a user’s account and facilitates direct recording using a mobile device’s microphone.
- Otter is automatically integrated into Zoom, so users of this meeting platform may find it a more accessible speech-to-text tool than others which don’t automatically lpug-in to Zoom
Features which are absent in Otter, which other tools such as HappyScribe do facilitate are the option to have human transcribers outsourced by HappyScribe to work on transcriptions and the ability to play video as well as audio during playback. As audio playback and automatic transcription proved sufficient, these were not necessary features for the IVO project and so were not factored into criteria for deciding on a tool.
Despite the advantages set out above, Otter has a number of limitations:
- Otter seems oriented towards creating transcriptions that prioritise legibility and coherence rather than preserving all elements of the original spoken discourse. As such, items such as repetitions and hesitations (for example uh, um, ah) are ignored and thus absent in transcripts. These can be time-consuming to reinsert.
- Otter can be frustrating to use when the user makes substantial edits as these can misalign audio and cause Otter to stall and limit playback. It can take substantial time to get Otter back into normal playback.
Procedure for using speech-to-text tool
Once a transcript has been created, it needs to be checked. The speed of transcription checking per minute is strongly determined by the transcript that is being reviewed and the elements of the transcript that are determined as necessary elements of the review process. For the IVO project, these elements of review were necessary but time-consuming components of the process:
- Checking for accuracy and editing accordingly,
- Inserting fillers (such as uh and um) which Otter is programmed to ignore,
- Insertion of symbols and codes for items like interruptions, coughs and non-verbal sounds,
- Anonymising any content that might reveal the identity of the participants or organisations involved.
The transcript review process is facilitated via Otter’s edit function. A user can listen to an uploaded audio file while the transcript is highlighted during playback. The user can double click on an item to edit that section of a transcript. As seen below, there are several playback options including changing the speed of payback and choosing to skip silences as seen in figure 1.
Figure 1: Screenshot of Otter’s playback options
The playback toolbar gives the user the option to rewind or skip forwards 5 seconds. It also has a highlight option, which was used for the IVO project to achieve step 4 above and highlight terms for anonymisation upon review. Anonymisation was carried out on a second review of the transcript separate from the accuracy review as anonymisation required the use of a document that lists codes for use for anonymisation and doing both accuracy check and anonymisation at the same time proved inefficient. There is a comment option which is useful for multiple reviewers to comment on the transcript in a side-margin for other users to read and an image option facilitates the integration of images into a transcript.
Exporting files for integration into a multi-modal corpus
As stated above, one of the key reasons why Otter was chosen for the IVO project is the flexibility of export options that it affords via its export screen (figure 2). The five format options it provides are clipboard, docx, pdf, txt and srt.
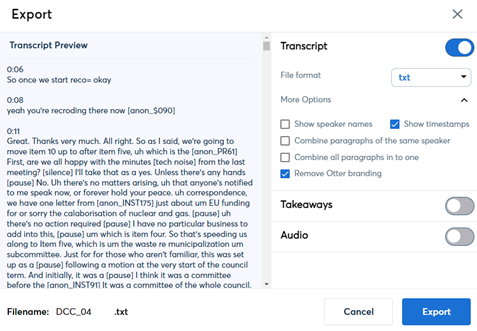
Figure 2: Screenshot of Otter’s export screen
SubRip (SRT) files are usually created for generating subtitles for video projects such as YouTube videos. SRT files are plain text files that include the text in sequence with start and end timecodes to align with video content. To determine the format of a subtitle on a screen, Otter gives options relating to number of lines and maximum characters per line as seen in figure 3. This formatting option is also of use to multi-modal orthographic transcript creation as this determines the parameters of segments (i.e. the spaces occupied on tiers into which annotations can be inserted) when imported into a multi-modal corpus tool.

Figure 3: Screenshot of Otter’s SRT file export settings
To illustrate how different export options effect segmentation in ELAN, see a screenshot in figure 4 of ELAN with tiers containing SRT imports of the same transcript with different attributes for line numbers and characters per line.
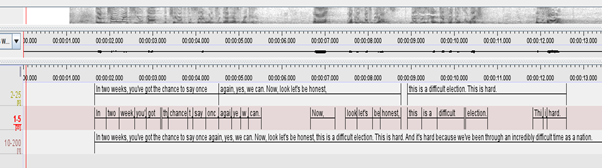
Figure 4: Screenshot of ELAN tiers showing imported SRT files with various settings
The settings chosen by a user when exporting from Otter, will be tailored to the extent to which they aim to have the text aligned with audio and readability in tiers when imported into ELAN. This segmentation will also determine subsequent parameters of chunks of transcription in outputs from ELAN. The three settings selected in Otter for the above three tiers in order from top to bottom are:
- Max number of lines – 2 , max characters per line – 25
- Max number of lines – 1 max characters per line – 5
- Max number of lines – 10, max characters per line – 200
While 2 above is the minimum that can be selected and results in the most fine-grained segmentation, 3 is the maximum and results in long segments. For the IVO project, we settled on the settings for 1 (2 lines, 25 characters) as this gives a balance of time-alignment and readability in ELAN. This still necessitated a degree of merging segments to fine-tune segments into meaningful chunks (i.e. phrases or clauses) but proved faster than the process of creating segments individually and inserting annotations in ELAN.
While speech to text tools remain less than completely accurate and the limitations listed above are significant, the multiple features and efficiency facilitated by its integration into the overall process of corpus construction leads us to conclude that it is advantageous to use such a tool. In addition, frequent upgrades to tools such as Otter and a competitive market provide evidence that these tools are evolving at pace. Improvements in AI speech-to-text technology and integration of features suitable for linguists (see Umair et al. 2022) will see substantial progression in the accuracy and efficiency of these tools in the future leading to more adoption for linguistic analysis and corpus construction.
Reference:
Umair, M., Mertens, J. B., Albert, S., & de Ruiter, J. P. (2022). GailBot: An automatic transcription system for Conversation Analysis. Dialogue & Discourse, 13(1), 63-95.